

Message
Message
The Illusion of Expertise
The rise of artificial intelligence in medicine has been accompanied by a peculiar phenomenon: the conflation of linguistic fluency with diagnostic competence. When a system can generate text that reads like an expert's assessment (e.g., complete with anatomical terminology, differential diagnoses, and confident conclusions) it becomes tempting to assume that the system possesses the expertise it mimics. This temptation is not mere carelessness; it reflects a deeply rooted cognitive tendency known as the confidence heuristic, whereby people judge the persuasiveness and accuracy of information according to the confidence with which it is expressed. Under normal circumstances, this heuristic serves us well: people tend to express confidence in proportion to their knowledge, so confident communicators are usually more accurate. However, experimental research has shown that the heuristic can be exploited. Groups are disproportionately influenced by their most confident member even when that member is wrong. Individuals with high dominance and low openness can persuade others even when they possess weak evidence, pointing to circumstances in which, as Pulford et al. note, "the confidence heuristic tends to break down and allow ignorance to overwhelm knowledge."
Large language models exploit this same vulnerability: they are designed to produce outputs that carry the linguistic markers of expertise (i.e., assertive phrasing, technical vocabulary, structured formatting) regardless of whether the underlying information is accurate. Unlike a knowledgeable human who calibrates confidence to the strength of their evidence, these systems maintain an unwavering authoritative tone whether they are correct or catastrophically wrong. The confident tone is a feature of the system's design, not a reliable signal of correctness. This chapter examines that manufactured confidence and the dangers it poses when artificial intelligence is deployed in contexts where the appearance of knowledge must not be mistaken for its substance. Figure 1 illustrates this critical distinction: in normal human communication, confidence reliably signals knowledge, but large language models produce confident outputs regardless of accuracy, breaking the link that the confidence heuristic depends upon.
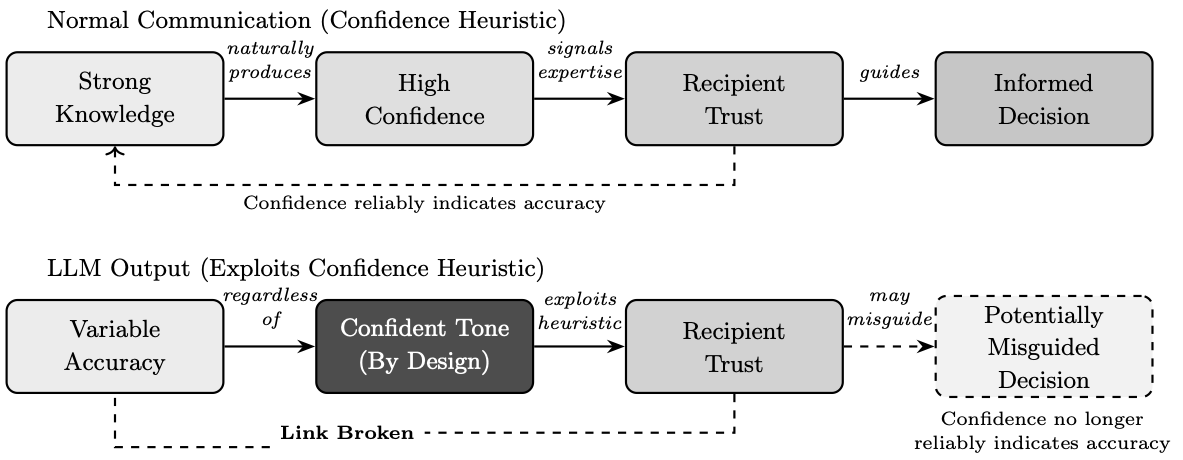
There exists, moreover, a subtler danger in the confident outputs these systems produce. Large language models are, at their core, sophisticated instruments of linguistic accommodation. They are trained to generate text that satisfies, that pleases, that aligns with the apparent expectations embedded in the prompts they receive. When one asks such a system to perform as a radiologist, it obliges with remarkable theatrical conviction, producing reports formatted with bullet points and technical terminology, offering differential diagnoses with the assured cadence of expertise. Yet this performance of competence must not be mistaken for competence itself. The reader of this chapter should approach all AI-generated medical interpretations with the same skeptical scrutiny one would apply to a beautifully written letter of recommendation from an author one has never met. The prose may be impeccable; the substance requires independent verification.
Recent studies investigating the diagnostic capabilities of large language models have attracted significant media attention, often resulting in headlines claiming that artificial intelligence systems can match or even outperform physicians. As these language models have rapidly proliferated, this has fueled a widespread misconception that they represent the cutting edge of artificial intelligence in all contexts. This narrative tends to overshadow the continued importance of task-specific machine learning models, which were developed and validated for particular diagnostic applications well before the rise of conversational AI. To empirically examine these limitations, Chapter 2 presents a single-case study evaluating five leading multimodal large language models on a standardized radiological interpretation task, complemented by a novel cross-evaluation protocol wherein each model graded all responses. The findings reveal fundamental diagnostic errors, clinically meaningful variability even among ostensibly concordant models, and irreconcilable disagreements between systems when tasked with evaluating one another. These results demonstrate that current multimodal large language models exhibit unacceptable diagnostic variability for autonomous clinical deployment and that healthcare applications requiring reliable image interpretation should prioritize validated, task-specific machine learning systems over general-purpose language models.
Key Point: The confident, authoritative tone of large language model outputs is a design feature, not a signal of accuracy. These systems exploit the human tendency to trust confident-sounding sources, producing polished, professional text regardless of whether the underlying information is correct. Linguistic fluency must not be mistaken for diagnostic competence, and general-purpose language models must not be mistaken for validated medical AI.
The Public Discourse
The public discourse surrounding artificial intelligence has become increasingly synonymous with large language models, those systems that have captured global attention since 2022 and transformed the popular imagination of what machines might accomplish. This conflation, while understandable given the unprecedented visibility these tools have achieved, obscures a fundamental reality: artificial intelligence as a field has been under active development for over half a century, and large language models represent merely the most recent, and in many respects most narrowly specialized, manifestation of a far broader technological landscape.
One might compare the situation to a person who, having recently discovered orchestral music through a particularly moving symphony, comes to believe that all music consists of symphonies. The symphony is indeed a magnificent form, capable of extraordinary emotional and intellectual expression. Yet to mistake it for the totality of musical possibility would be to overlook chamber music and opera, folk songs and jazz improvisations, the vast heritage of musical invention that preceded and surrounds it. So too with large language models: they represent one powerful approach within a diverse ecosystem of artificial intelligence techniques, each with distinct capabilities and limitations.
Key Point: Large language models are just one type of artificial intelligence among many. Their recent popularity has created a false impression that they represent the best AI solution for every problem, when in fact specialized AI systems designed for specific tasks often perform far better in their intended domains.
A Brief History of Artificial Intelligence
Understanding why large language models are ill-suited for medical image interpretation requires situating them within the broader landscape of artificial intelligence, a field whose seven-decade history has produced diverse approaches to machine cognition, each with distinct strengths and limitations. The current public fascination with conversational AI obscures this rich technological heritage and, more critically, the specialized diagnostic tools that emerged from it.
The foundations of artificial intelligence were laid in the 1950s. Alan Turing's seminal 1950 paper, titled "Computing Machinery and Intelligence," posed the question of whether machines could think, and proposed what would come to be known as the Turing Test as a practical criterion for machine intelligence. The 1956 Dartmouth Conference, organized by John McCarthy, Marvin Minsky, Nathaniel Rochester, and Claude Shannon, formally established artificial intelligence as a field of academic inquiry, bringing together researchers who believed that "every aspect of learning or any other feature of intelligence can in principle be so precisely described that a machine can be made to simulate it."
In the decades that followed, AI research progressed through multiple paradigms, each reflecting different beliefs about how intelligence might be computationally realized. The 1960s through 1980s saw the dominance of symbolic reasoning and expert systems, approaches that attempted to encode human knowledge as explicit rules and logical relationships. These systems could perform impressively within narrow domains where expert knowledge could be systematically articulated, yet they proved brittle when confronted with situations their designers had not anticipated.
The 1980s and 1990s witnessed neural network revivals, as researchers returned to biologically inspired architectures that had fallen out of favor. The backpropagation algorithm, popularized by Rumelhart, Hinton, and Williams in 1986, provided a practical method for training multilayer neural networks, enabling them to learn complex patterns from data rather than requiring explicit programming. Yet computational limitations of the era constrained what these networks could achieve.
The machine learning renaissance of the 2000s and 2010s, driven by increased computational power and unprecedented data availability, transformed the field. Deep learning architectures, particularly convolutional neural networks (systems specifically designed to process grid-like data such as images by applying learned filters across spatial dimensions), achieved breakthrough performance in image recognition tasks by the early 2010s. These achievements occurred years before the transformer architecture that underlies modern large language models was even conceived.
The transformer architecture, a neural network design that processes sequential data through a mechanism called "attention" (which allows the model to weigh the relevance of different parts of the input when producing each part of the output), was introduced in 2017. Foundational models such as BERT and GPT emerged in 2018. However, it was not until GPT-3 in 2020, with its 175 billion parameters (the adjustable numerical values that the model learns during training), that large language models began to demonstrate the conversational fluency that would later captivate public attention. The release of ChatGPT in November 2022 marked the inflection point at which these systems transitioned from technical curiosities to mainstream phenomena. In this context, the entire history of publicly prominent large language models spans barely three years, a tiny fraction of artificial intelligence's seven-decade evolution.
Key Point: Artificial intelligence has been developing for over 70 years, with many different approaches created for different purposes. For decades, the quiet work of building artificial minds went unnoticed. And yet, it is only in these recent years that large language models have sprung forth, suddenly and vividly, as if they had always been there, waiting for the world to notice. The specialized AI systems designed specifically for medical imaging were developed and proven effective long before conversational AI became popular.
The Misconception
The explosive visibility of large language models has fostered a pervasive misconception: that "AI" and "LLM" are interchangeable terms, and that these language-centric systems represent the state of the art across all artificial intelligence applications. Such conflation complicates ongoing efforts to define AI's transformative potential in healthcare and navigate its ethical implications. Misunderstanding the distinction can have serious consequences, particularly in domains where task-specific machine learning models, developed and validated long before the current era, remain the appropriate technological choice.

The very nomenclature is instructive. Large language models are, by design and training objective, optimized for linguistic tasks: text generation, summarization, translation, and conversational interaction. Their architecture, the transformer, was developed specifically for sequence-to-sequence modeling in natural language processing, a field concerned with enabling computers to understand and generate human language. While multimodal variants have emerged that can process images alongside text, with applications extending to domains such as orthodontic biomechanical reasoning, these capabilities represent extensions grafted onto a fundamentally language-centric architecture, not systems purpose-built for visual analysis.
The viral launch of ChatGPT in November 2022 marked an inflection point in public awareness of artificial intelligence capabilities (Figure 2). Within months, large language models transitioned from specialized research tools to household technologies, fundamentally altering public expectations regarding AI performance across diverse domains. This rapid mainstreaming, however, has fostered a pervasive misconception: that general-purpose language models represent the state of the art across all artificial intelligence applications, including medical image interpretation.
As illustrated in Figure 2, this perception obscures a critical distinction. Task-specific machine learning models, developed, validated, and in many cases regulatory-cleared for defined diagnostic imaging tasks, have been advancing through detailed clinical validation pathways for decades. These systems remain the appropriate technological choice for applications requiring reliable, reproducible diagnostic accuracy. The conflation of language model capabilities with validated medical AI risks inappropriate deployment of unvalidated tools in contexts where patient safety demands proven performance.
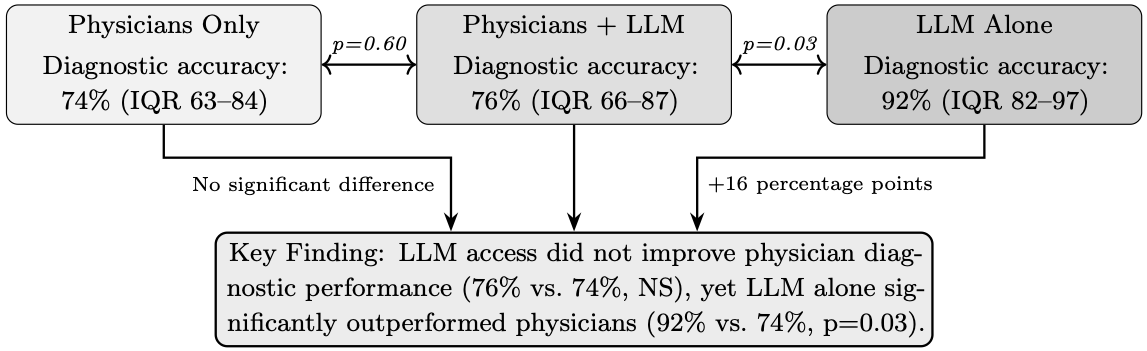
Recent studies examining the diagnostic capabilities of large language models have garnered substantial media attention, often generating headlines that proclaim AI systems can match or exceed physician performance. Figure 3 illustrates findings from a randomized controlled trial by Goh et al., in which a large language model alone achieved a diagnostic reasoning score of 92%, significantly higher than physicians using conventional resources (74%, p=0.03). Such results, when reported without context, fuel public perception that these systems represent reliable diagnostic tools ready for clinical deployment.
However, it is necessary to note that the Goh study evaluated performance on text-based clinical vignettes, a task that leverages the core linguistic reasoning capabilities for which these models were designed. Medical diagnosis in practice frequently requires interpretation of imaging studies, ranging from cross-sectional imaging to specialized reports such as visual field tests, a fundamentally different task that tests the multimodal visual capabilities of these systems rather than their text-processing strengths.
Key Point: Headlines claiming AI can match doctors are often based on tests involving written case descriptions, which is exactly what language models are designed to handle. Real medical diagnosis often requires interpreting images, which is a very different skill that these language-focused systems were not primarily built for.
Machine Learning in Radiology
The application of machine learning to medical imaging predates the large language model era by decades, as illustrated in Figure 2. Foundational work began in the early 1960s, when Lodwick and colleagues introduced the first computational analysis of chest x-rays for lung cancer classification using manual feature coding and rule-based computer analysis. Lodwick subsequently coined the term "computer-aided diagnosis" (often abbreviated as CAD, referring to computer systems that assist physicians in interpreting medical images) and outlined a research plan for automated classification of radiological images.
Throughout the 1970s, these methods advanced significantly. Kruger and colleagues applied automated feature extraction and statistical classification to chest radiographs for cardiac analysis. Toriwaki and colleagues employed image processing and pattern recognition to automatically measure the cardiothoracic ratio, a standard measurement comparing heart size to chest width. Further work by Kruger and colleagues advanced pattern recognition techniques for automated abnormality detection in chest radiographs. These early efforts laid the groundwork for computer-aided diagnosis systems for mammography, which received FDA approval as early as 1998.
Deep learning approaches to radiological image analysis began demonstrating expert-level performance in the mid-2010s. Landmark studies showed that systems based on convolutional neural networks (a type of neural network specifically designed to process images by learning spatial patterns through layers of filters) matched or exceeded dermatologist accuracy in skin lesion classification (2017), radiologist performance in chest X-ray interpretation (2017–2018), and ophthalmologist accuracy in diabetic retinopathy screening (2016). Recent comprehensive reviews have further documented the expanding applications of machine learning across medical imaging modalities.
These systems share a critical characteristic: they are task-specific. A convolutional neural network trained to detect acute ischemic stroke (a condition where blood supply to part of the brain is interrupted, causing brain tissue damage) on non-contrast head computed tomography has been optimized exclusively for that task, with training datasets comprising thousands to millions of expert-annotated images of that specific pathology in that specific imaging modality. This focused training enables the model to learn the precise visual features that distinguish pathology from normalcy in that defined context. These features include subtle hypodensities (areas that appear darker than surrounding tissue, indicating reduced tissue density), loss of gray-white differentiation (blurring of the normally visible boundary between gray matter and white matter in the brain), insular ribbon signs (loss of definition in a specific brain region called the insular cortex), and hyperdense vessel signs (abnormally bright appearance of blood vessels indicating a clot). Similar validation strategies have been applied successfully to automated MRI-based classification tasks in neurological diagnosis, demonstrating the efficacy of task-specific approaches.
By contrast, multimodal large language models acquire their image interpretation capabilities as a byproduct of training on heterogeneous image-text pairs scraped from diverse internet sources. Medical imaging content constitutes a small and potentially unrepresentative fraction of this training corpus. The resulting systems possess broad but shallow capabilities: they can describe what they "see" in an image using medically plausible language, but their visual representations have not been optimized for the discriminative features that matter for specific diagnostic tasks. Comparative studies examining multimodal large language models against purpose-built feature extraction methods in clinical contexts, such as autism prediction from home videos, further illuminate these architectural limitations.
Key Point: AI systems designed specifically for medical imaging have been developed and improved for over 60 years. These specialized systems are trained on thousands or millions of carefully labeled medical images for one specific task, learning exactly what visual features indicate disease. General-purpose language models, by contrast, learned about medical images incidentally while training on vast amounts of internet content, making their medical imaging abilities broad but superficial.
The Critical Distinction
The core competency of a large language model is generating contextually appropriate text. When presented with a medical image, a multimodal language model generates a textual description that is linguistically coherent and stylistically consistent with radiological reporting conventions. This output may appear authoritative, formatted in bullet points, employing correct anatomical terminology, offering differential diagnoses, yet the relationship between this generated text and the actual pixel-level content of the image is fundamentally different from that of a purpose-trained diagnostic model.
Consider the distinction carefully, for it illuminates a profound difference in how these systems relate to truth. A task-specific stroke detection system processes the image through layers of learned convolutional filters optimized to detect the visual signatures of ischemic injury. Its output, indicating stroke present or absent with localization, is a direct function of learned visual features validated against confirmed diagnoses. Standardized validation frameworks for clinically actionable machine learning models emphasize the importance of detailed performance characterization across diverse datasets. The system's errors are systematic and discoverable through rigorous validation. One can quantify its sensitivity (the proportion of true positive cases correctly identified), specificity (the proportion of true negative cases correctly identified), and predictive values. Its failure modes can be characterized and understood.
A large language model, by contrast, generates a textual response that is statistically consistent with the kinds of reports that accompanied similar-seeming images in its training data. The model is not "diagnosing" in any meaningful sense; it is predicting what text a radiologist might have written, based on pattern matching against its training distribution. The elegant prose and confident assertions emerge from linguistic probability distributions, not from any genuine understanding of the visual features present in the image.
This distinction has profound implications for reliability. A well-validated task-specific model has quantified performance characteristics: known sensitivity, specificity, positive and negative predictive values, and characterized failure modes. An LLM's errors, by contrast, are emergent properties of a system not designed for the task at hand, potentially unpredictable, and difficult to characterize systematically. The model might produce a perfectly formatted radiology report that is nonetheless entirely wrong, and do so with complete linguistic confidence.
Key Point: A specialized medical AI actually learns to recognize disease patterns in images, and its accuracy can be measured and verified. A language model, however, generates text that sounds like what a radiologist might write, based on patterns in its training data. This means the language model can produce confident, professional-sounding reports that are completely incorrect, because its skill is in generating plausible text, not in truly understanding what is in the image.
Contact Us
Phone
+1-516-686-3765
Address
Dept. of Osteopathic Manipulative Medicine
College of Osteopathic Medicine
New York Institute of Technology
Serota Academic Center, room 138
Northern Boulevard, P.O. Box 8000
Old Westbury, NY 11568
mtoma@nyit.edu